
Talk to a product expert
5 Technical Decisions that made the AutoReview the most Capable AI Review Agent in Engineering


Almost all AI design review tools work the same way.
Provide your file, it gets passed to an underlying LLM which then returns a response based on general knowledge.
The output often sounds reasonable. It uses the right terminology.
But if you're an engineer who actually knows the design, you can tell the difference. The findings are generic. The explanations are surface-level. And the tool clearly doesn't understand the nuances of the engineering data it's been given.
That's not a failure of AI. It's a limitation of the approach to applying it for engineering design review. A general-purpose model currently has no way of reliably structuring engineering data before analyzing it, so it works with what it gets, whether that's a drawing in PDF format or a flat image of a 3D model.
AutoReview was built to close that gap. Over the past year, working directly with hundreds of engineering teams, we've made five technical decisions that separate AutoReview from anything else on the market, and make it the most capable AI review agent in engineering.
Let's look at each one in more depth.
AutoReview interprets engineering files differently than any other LLM
This is the foundation everything else is built on.
When you upload a drawing to a general-purpose AI tool, the model receives a flat image — or at best, a raw text extraction. It has no structure to work with. It doesn't know which region is a title block and which is a BOM. It can't distinguish a GD&T feature control frame from a general note. It can't tell which dimension is associated with which feature.
So it guesses. And guessing is where errors and hallucinations come from.
We identified this as the single biggest gap in how AI tools handle engineering files, so we built a proprietary processing method to close it.
Before any analysis runs, AutoReview processes and structures the contents of your drawing. It knows what's on the page, where it is, and how different elements relate to each other. A dimension on View B, a tolerance in the title block, a note referencing a specific feature — AutoReview understands these as connected pieces of engineering data, not isolated text on a page.

That's why its findings reference actual content on your drawing. Instead of a generic observation about "possible dimensional inconsistencies," AutoReview can tell you that a specific dimension on View B conflicts with the tolerance specified in the title block.
This is the difference between AI that scans a drawing and AI that understands one.
Specialized agents, not one general model
Many AI review tools are built on a single general model, which then makes a single pass and tries to say something useful about what it’s seeing. The result is typically a handful of useful insights buried in broad, shallow observations that an experienced engineer either already knows or could easily catch on their own.
AutoReview takes a fundamentally different approach.
Instead of one general analysis, it deploys a collection of proprietary review agents. Each one is purpose-built for a specific domain of engineering review, and AutoReview selects which agents to deploy based on what's actually present in the file.
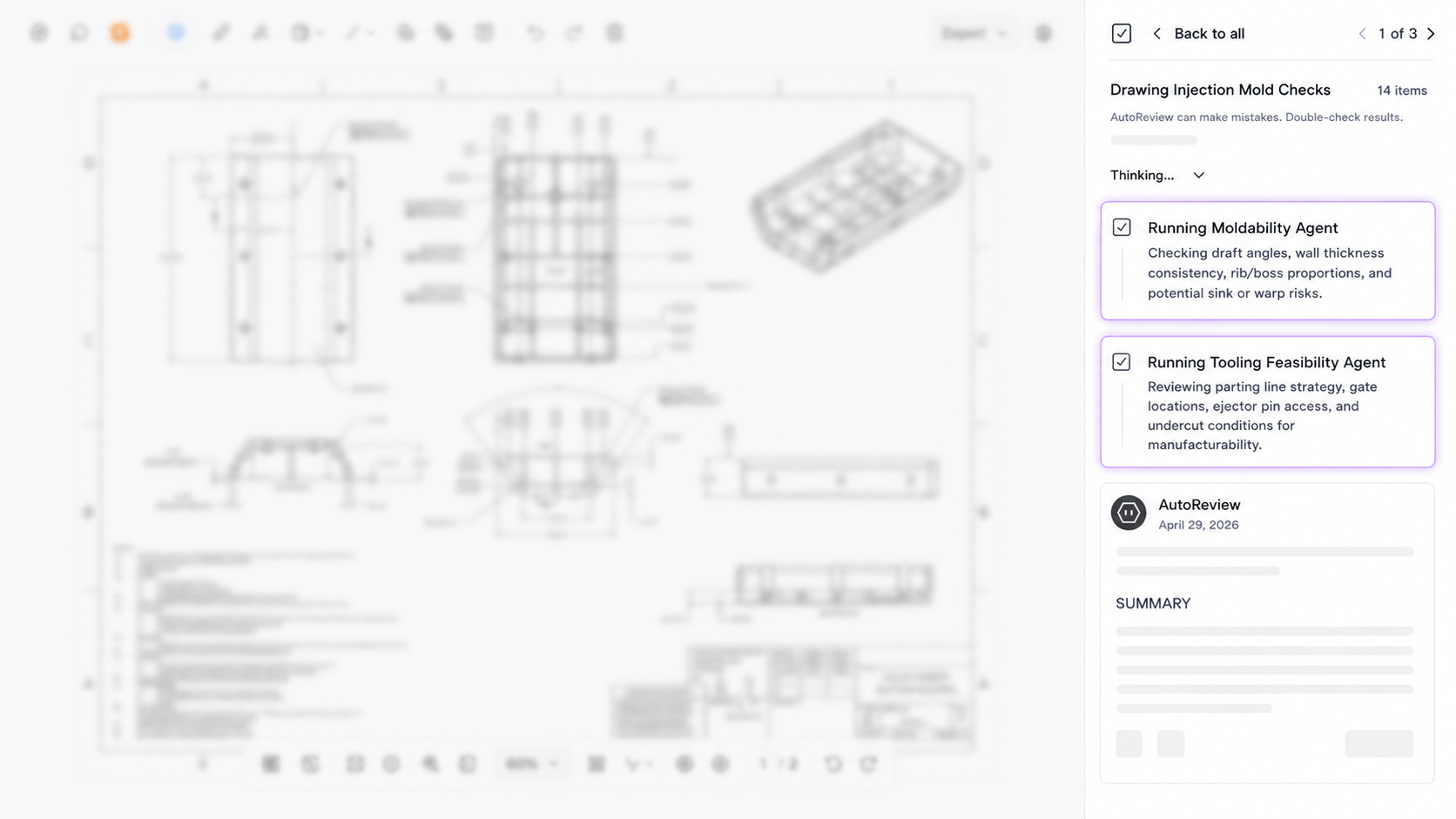
The key difference is the explicit focus of each agent. A tolerancing agent evaluates tolerancing in the context of tolerancing. It isn't distracted by the title block. A material consistency agent isn't parsing section views. Each agent works with exactly the slice of design data relevant to its domain.
This is what makes the output specific rather than generic. And over time, we've refined each agent across millions of operations on thousands of engineering files to reduce noise and increase relevance.
It uses your standards, not just general knowledge
A general-purpose LLM reviews your drawing against whatever engineering knowledge exists in its training data. That might be useful for catching textbook errors, but it has no knowledge of your company's standards, your industry's specific requirements, or the criteria your team actually reviews against.
AutoReview works differently.
Teams upload their standards and guidelines documents once. From that point forward, AutoReview references them in every run, and cites the specific standard behind each finding. If your organization has internal GD&T conventions, material specifications, or drawing practices that go beyond or differ from generic ASME or ISO guidelines, AutoReview considers this.
.png)
Beyond standards documents, teams can build custom checklists that direct which aspects of the review are prioritized. And users can provide material and manufacturing context before a run, so the analysis is grounded in the actual manufacturing method, not a generic assumption.
Without this, AI feedback is judged against a generic baseline. With it, feedback is judged against the same standards your team uses in review. A finding that says "this tolerance may be too tight" is generic. A finding that says "this tolerance conflicts with Section 4.2 of your internal design standard" is actionable.
[IMAGE: AutoReview finding with an inline S&G citation — showing the specific standard referenced in the finding, ideally with the split-view where the source document is visible alongside the drawing]
It combines AI with deterministic analysis
For 3D models, we made a fundamental architectural decision: not everything should be handled by an LLM.
Some engineering checks don't require interpretation. They require measurement. When you need to know whether a wall is thick enough, whether a bend radius is within limits, or whether a hole is too close to an edge for a given manufacturing process, those are questions with definitive answers based on the geometry itself.
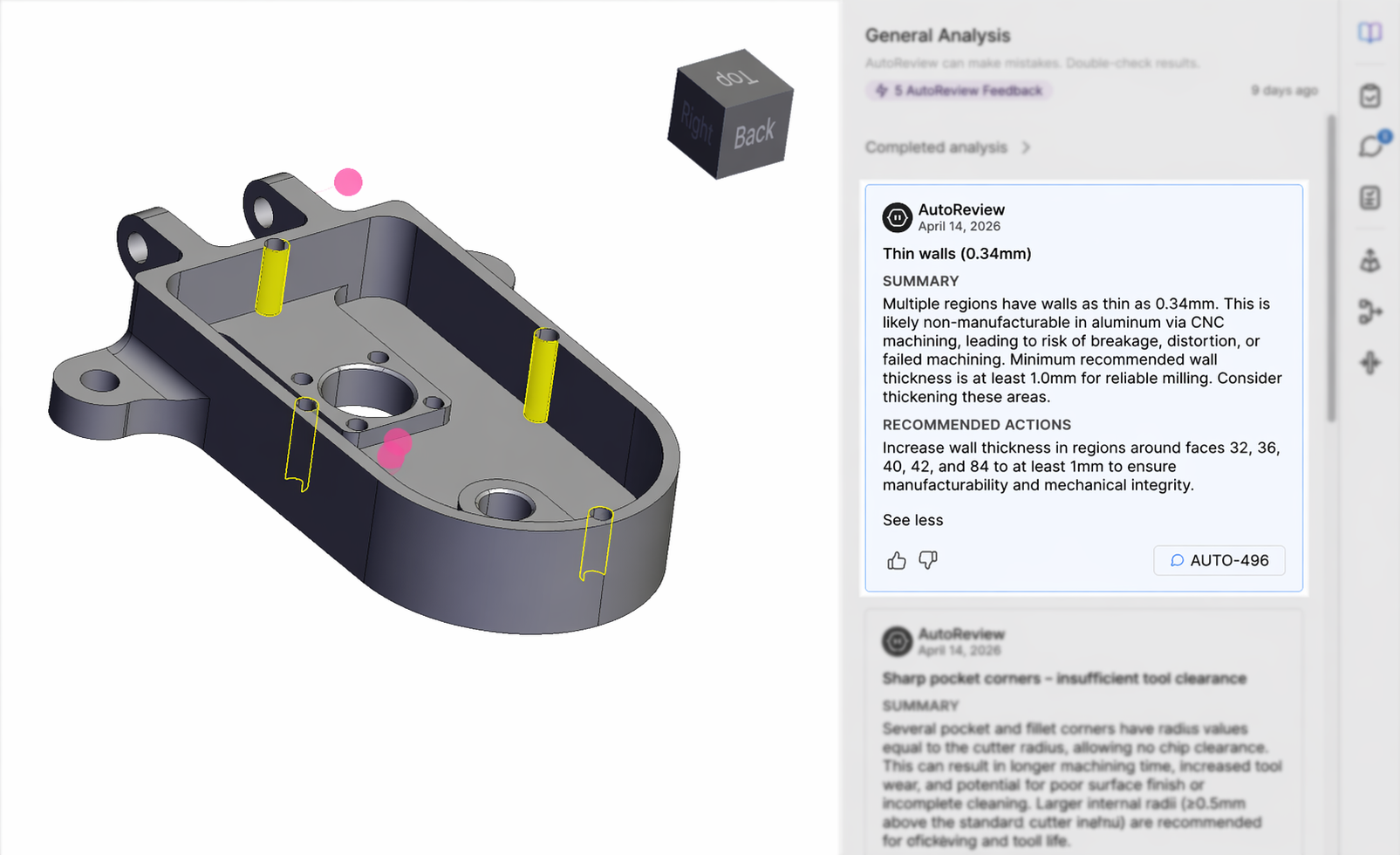
So AutoReview runs both.
Deterministic checks handle the questions that can be answered by measuring the actual geometry against known manufacturing thresholds. AI-based agents handle the checks that require contextual reasoning: design intent, standards interpretation, cross-referencing annotations.
This matters because it directly addresses one of the most common objections to AI in engineering: "How do I know it's right?" For the deterministic checks, the answer is simple: the geometry was measured, not interpreted.
But measurement alone isn't enough. A raw DFM output that says "wall thickness: 0.8mm, minimum: 1.2mm" is accurate, but it requires the engineer to interpret what that means for their specific part and process. AutoReview's AI layer reasons on those measurements, contextualizing them against the part's material, manufacturing method, and design intent, and communicates each finding in plain language with a specific recommendation for what to change and why.
Every finding flows directly into a human decision-making workflow
This is the decision that separates AutoReview from every other AI tool in the space.
AutoReview doesn't generate a PDF report that sits in a folder. It doesn't produce a chat response that someone has to manually transfer into another system. Every finding lands directly in a collaborative review, alongside the actual design file, the full context of the review, and feedback from human reviewers, all in one place.
This is what makes the workflow complete. The engineer isn't switching between a report in one tab, the CAD file in another, and a spreadsheet tracking who's responsible for what. The design, the AI findings, and the human decisions all live together. An engineer can see the finding, inspect the relevant geometry or annotation on the actual file, and make a decision, without ever leaving the review.
That matters because AI can surface a potential issue, but only an engineer with full design context can determine whether it's a real problem, a known tradeoff, or irrelevant to the application.
A wall thickness flag might be critical on one part and intentional on another. A missing tolerance might be a genuine oversight or a deliberate simplification for a prototype run. A material callout might conflict with the title block, or it might reflect a revision that hasn't been formally updated yet.
These are engineering judgment calls that require human context, institutional knowledge, and an understanding of the specific application. Making those calls well requires having the design in front of you, not just a summary of it.
By bringing together the design file, the AI findings, and the engineering team into a single review workflow, AutoReview ensures that every AI output is subject to engineering judgment before it influences a decision. AI doesn't replace the review process. It makes it more thorough, and drives optimal design decisions.
What this adds up to
The difference between an AI tool that sounds like it understands engineering and one that actually does isn't just the underlying AI model. It's everything around the model.
How the file is processed before analysis. Whether the agent is built for the specific review task or generalized across all of them. What standards and context it has access to. What's measured against the geometry versus interpreted by an LLM. And where the output lands when the review is done.
These are the core decisions that differentiate AutoReview. None of them were easy to build. Most of them aren't visible from the outside. But they are the reason AutoReview's findings are specific, defensible, and grounded in the way engineering teams actually work.
AutoReview surfaces what's worth reviewing. The engineer decides what to do about it. That's how a review gets faster without getting weaker, and how a team catches more without slowing down.







About the author
Cody Colbert is a Product Marketing Manager at CoLab Software, focused on emerging AI applications in hardware engineering and product development.
