
Talk to a product expert
AI for Engineering: How to Capture Design Intent with Knowledge Bases


Most AI tools for engineering sound useful — until you try to use them in real engineering workflows.
AI agents can generate suggestions and sound confident. But they don’t know your drafting standards, your supplier constraints, or why your team made specific tradeoffs. Without that context, their recommendations don’t hold up in review and engineers tend to ignore them.
“Context engineering is everything when it comes to agents,” explains CoLab’s Machine Learning Engineer Essam Gouda. “Agents are too general when they don't have your context.”
That’s the gap we need to address.
AI agents don’t fail because they lack intelligence. They fail because they don’t have access to the decisions, rationale, and constraints behind your designs.
In practice, that means they make vague suggestions like “Increase wall thickness” or “Adjust tolerance" without knowing the manufacturing process, supplier limits, or what failed on similar geometry before.
To be useful in real workflows, AI needs more than rules. It needs design intent.
The teams seeing real value from AI are doing something different. They are building engineering knowledge bases that capture design intent, so their systems can reference past decisions, apply internal standards, and give context-aware guidance.
In this article, we’ll show:
- Why AI agents fail without context
- What “design intent” actually includes
- How engineering teams are structuring knowledge so AI can use it
- What a usable engineering knowledge base actually looks like
If you are evaluating tools, this connects directly to how teams are using AI agents for engineering design and improving design review workflows where this knowledge is actually created.
Why AI Agents Fail Without Design Intent
In engineering, a suggestion without context is noise. Estimates vary on how often LLMs get things right, but one Salesforce study said that “generic LLM agents achieve only around a 58% success rate in scenarios involving giving a direct answer without clarification steps.”
That failure rate is why you need an AI agent trained for you. A response from an LLM such as “Increase wall thickness” is a generic suggestion that will fail to move your project forward.
It only helps if the system knows specific context, such as:
- The manufacturing process and inspection method.
- The supplier limits for this part family.
- Internal drafting and GD&T expectations.
- What failed before on similar geometry.
- Which exceptions were intentional, and why.
When the agent can’t access that context, engineers will either ignore it or waste time debating it. The goal with an AI agent is that it contains all of the information that you have and can learn to apply your engineering judgment consistently. The question is how to do this.
In high-performing engineering teams, AI doesn’t rely on generic rules. Instead, it can:
- Reference similar designs and what went wrong
- Apply internal standards in context
- Account for supplier constraints and process limits
- Show the rationale behind past decisions
Rather than generic suggestions, the output is grounded in how your team actually builds products.
So what does "design intent" truly involve?
What “Design Intent” Actually Includes
In practice, useful engineering knowledge is far more than a standards PDF and a checklist. Rather, it is a complex web that includes:
- Standards and guidelines: Internal drafting rules, DFM guidance, and inspection requirements.
- Decisions and rationale: What you chose, what you rejected, and why.
- Lessons learned: Rework drivers, supplier feedback, field issues, and repeat escapes.
- Exceptions: “We normally do X, except on this product line.”
- Design context: Geometry, metadata, manufacturing details, revision history, and where an issue appears on the model or drawing.
That’s why a collected wiki of information alone rarely works. The value is in the links between decisions, files and outcomes. An AI must accumulate context in order to make good decisions or a human must be in the loop to provide that context to the AI.
Why Most Engineering Knowledge is Unusable Today
Many organizations already have “lessons learned." But they are hard to use at the moment of need, as the information is typically scattered in multiple places in the organization.
The Typical Failure Cycle:
- Issues get logged after a program ends.
- A spreadsheet or slide deck gets saved, but not in a place everyone knows.
- The next program starts.
- Nobody reviews the prior information.
- The same problems return.
Two failure modes show up frequently as a result:
- People do not know what to search or where.
- The lesson is not tied to the exact drawing view, feature, process or supplier.
The problem of maintaining knowledge is one that software like CoLab is designed to solve. It retains accumulated knowledge because it tracks all design review feedback within the system. This collection of information is crucial in order for an AI agent to function specifically for your designs. This accumulated collection is the beginning of your knowledge base.
Trust Requirements: Traceability and Audit Trails
After a decision is made, engineering teams need more than “an answer.” They need decision traceability.
A practical bar for an AI decision audit trail is:
- Every suggestion points back to its source.
- You can see the related standard, decision, or prior issue.
- You can tell if it applies to the current revision.
Good AI software currently allows for this.
What Good Teams Do Differently: Capture Knowledge During Design Reviews
If you want agents to use and re-use your knowledge, you need two things:
- Capture decisions where they happen.
- Structure them so they can be queried reliably.
Design reviews are the best source because that’s where engineers explain the why of what they are doing. That includes the edge cases and tradeoffs that never make it into a standard.
CoLab’s ability is to turn review activity into reusable knowledge without asking engineers to do extra admin work.
That structured layer is what creates an engineering knowledge graph. These are key in ensuring any software can assist making decisions.
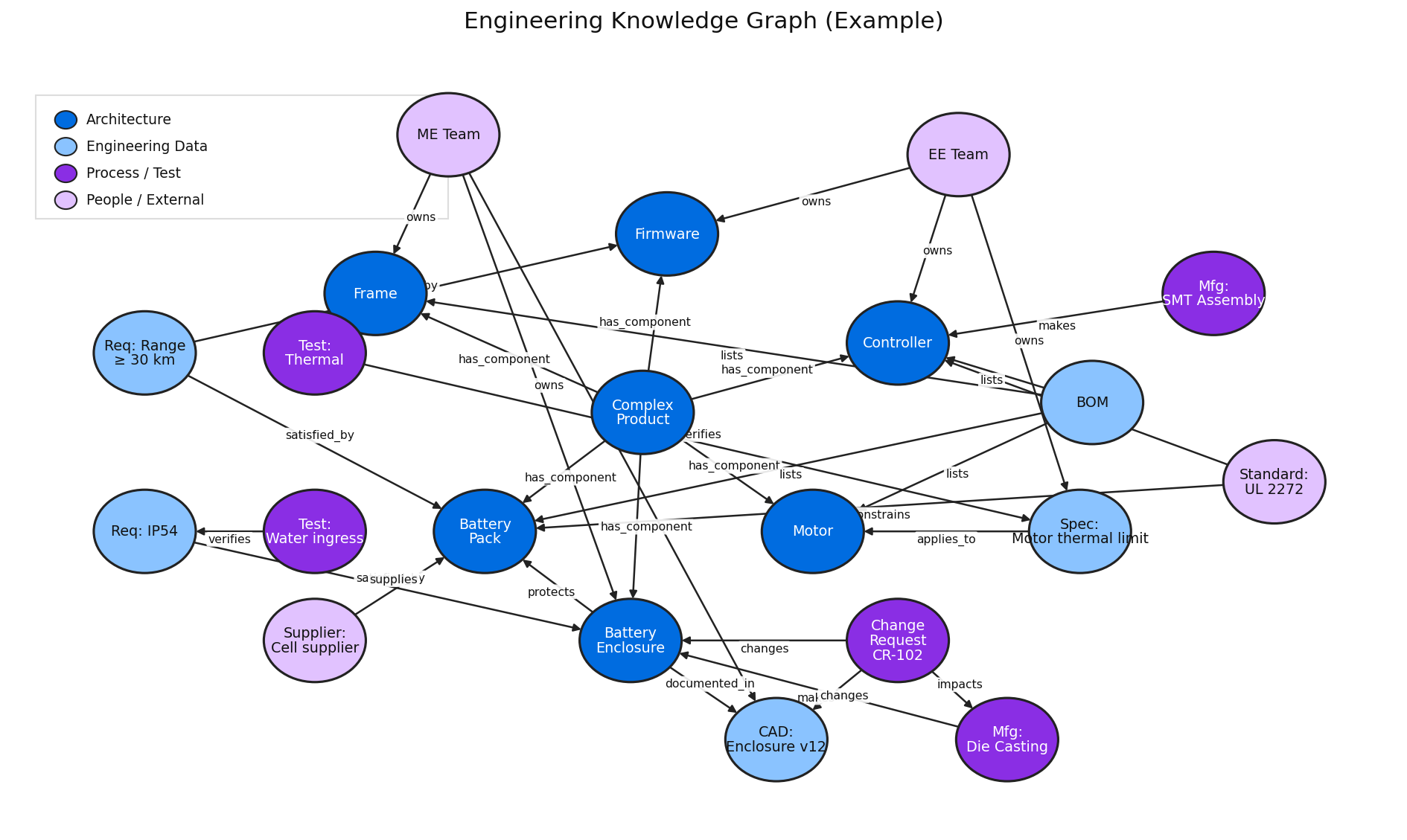
What Changes When Knowledge is Structured Correctly
A graph is useful because it represents relationships, not just files. In engineering, that looks like:
- A drawing note linked to a part family and process.
- An issue type linked to a supplier constraint.
- A decision linked to a revision and approver.
- A lesson learned linked to similar geometry and the fix.
What is being built is a body of information that an AI agent is able to query easily. It can find information and quickly deliver it to the LLM so that it can provide sufficient context to make a good decision.
“Let's say we have multiple documents,” explains CoLab’s Machine Learning Engineer Essam Gouda. “Each of them are speaking to different topics but some pages or sections overlap. A knowledge graph should be built in a way where if you reach one part of a document, you can easily find the relative sections in other documents or in other pages of the same document on that subject.
“Essentially, if you find at least one relevant chunk in the document, you should be able to find all the other relevant chunks easily. That’s what a knowledge graph does.”
Example Scenario:
- Question: “Show me similar brackets and what went wrong last time.”
- Answer: The agent retrieves similar designs, repeat issues, the decision history, and how it was resolved.
That is what makes an agent feel grounded in your organization, instead of generic. Right now this works with elements such as your standards and guidelines as well as GD&T.
But as the AI learns, and as software manufacturers build out the AI’s capabilities, the next phases of AI will allow it to do much more.
“Once we have more data, once we have a lot of likes and dislikes, we can start tweaking our flows to match what the clients expect,” says Gouda. “You’re essentially making new standards and guidelines based on the information you have accumulated.”
Absorbing that information into a digital platform is crucial. Senior engineers often answer the same questions from memory repeatedly. A knowledge layer changes that pattern.
If you capture design intent, a new hire can ask the system and get:
- The past review where the topic came up.
- What options were considered.
- Who approved the choice.
- What problem it prevented.
This supports engineering knowledge retention and prevents the "brain drain" of context leaving with people. AI agents such as CoLab can do this element today.
“Let's say we have multiple documents. Each of them are speaking to different topics but some pages or sections overlap. A knowledge graph should be built in a way where if you reach one part of a document, you can easily find the relative sections in other documents or in other pages of the same document on that subject.”
- CoLab’s Machine Learning Engineer Essam Gouda.
Where This is Going: AI Agents in Real Engineering Workflows
As tools, AI agents are in their infancy. The tools will continue to evolve. This is where AI agents are heading as tools.
1. Drawing Review and Automated QA
Drawing review is high volume and high consequence. This is where tools like AI engineering drawing checkers will create immediate ROI by flagging:
- Material callouts that do not match metadata.
- Duplicate dimensions.
- Title block inconsistencies.
- Missing tolerances and common GD&T issues.
Instead of only flagging a potential issue, an AI checker will be able to surface prior decisions on similar designs and understand the context behind them. This turns “error detection” into trusted review assistance.
2. DFM Feedback That Becomes Local, Not Generic
DFM is not only universal rules. This is something that suppliers and teams have often learned the hard way.
- Generic Rule: "Avoid sharp internal corners."
- Real Rule: "It’s fine on this part family and with this supplier process."
In time, an AI agent will be able to reference past reviews and similar parts so that it can give process-aware guidance and prioritize issues that actually drive rework.
Buyer Checklist: How to Evaluate Knowledge-Powered AI Agents
The following questions can help you separate tools that sound capable from systems that actually reflect how engineering work gets done.
- [ ] Can it use our internal standards and past decisions, not only public data?
- [ ] Does it show evidence and context for each suggestion?
- [ ] Does it capture knowledge during real work, or require manual tagging? Q2/Q3
- [ ] Will it work with your existing PLM and issue trackers?
- [ ] Can we control access for suppliers and protect sensitive design data?
If the answer is “no” to most of these, it will not improve engineering decisions now or in the future.
Any AI software you purchase must be building up knowledge of your specific business and processes or it will be of very limited value.
“We don’t want to have general agents,” says Gouda. “We want specific mechanical engineering agents.”







About the author
Jon Filson is an industry analyst and writer for CoLab. Email him at jonfilson@colabsoftware.com.
